KV-Cache Layout in FlashInfer¶
Layout: NHD/HND¶
FlashInfer provides two layouts for last 3 dimensions in KV-Cache: NHD and HND:
NHD: the last 3 dimensions are organized as(seq_len, num_heads, head_dim).HND: the last 3 dimensions are organized as(num_heads, seq_len, head_dim).
The NHD layout is more natural because it’s consistent with the output of
\(xW_k\) and \(xW_v\) without transpose. The HND layout is more friendly
for GPU implementation when KV-Cache uses low-precision data type (e.g. fp8).
In practice we don’t observe significant performance difference between these two layouts
on fp16 kV-Cache and we prioritize NHD layout for better readability. FlashInfer implements
Attention kernels on both layouts and we provide an option to select between them (NHD
by default).
Ragged Tensor¶
We use Ragged Tensor to store the variable length Q/K/V tensors in FlashInfer for batch prefill self-attention:
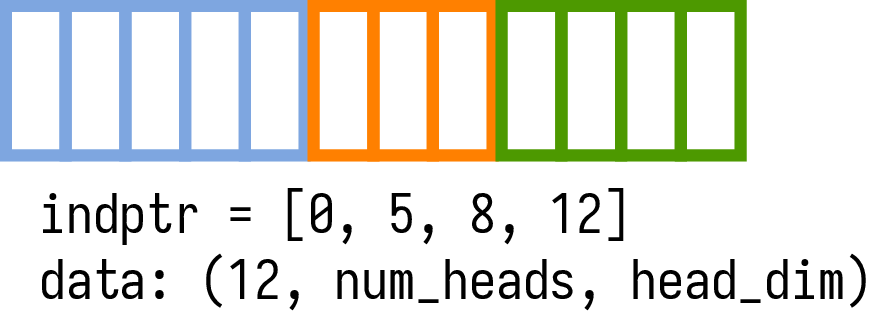
In Ragged Tensor, all requests’s Q/K/V are packed into a single data tensor without padding,
we use a indptr array (num_requests+1 elements, the first element is always zero)
to store the information of variable sequence lengths of each request
(indptr[i+1]-indptr[i] is the sequence length of request i), the data tensor has
shape (indptr[-1], num_heads, head_dim) when the layout is NHD.
We can use data[indptr[i]:indptr[i+1]] to slice the keys (or values) of request i.
Note
indptr arrays across the flashinfer library should be of type int32. Arrays of type int64 can cause indexing errors.
FlashInfer APIs¶
FlashInfer provides flashinfer.prefill.BatchPrefillWithRaggedKVCacheWrapper to compute
the prefill attention between queries stored in ragged tensor and keys/values stored in ragged
KV-Cache.
Mask Layout (2D Ragged Tensor)¶
The aforementioned Ragged Tensor can be generalized to multiple “ragged” dimensions. For example, the attention mask in FlashInfer is a 2D ragged tensor for batch size greater than 1:
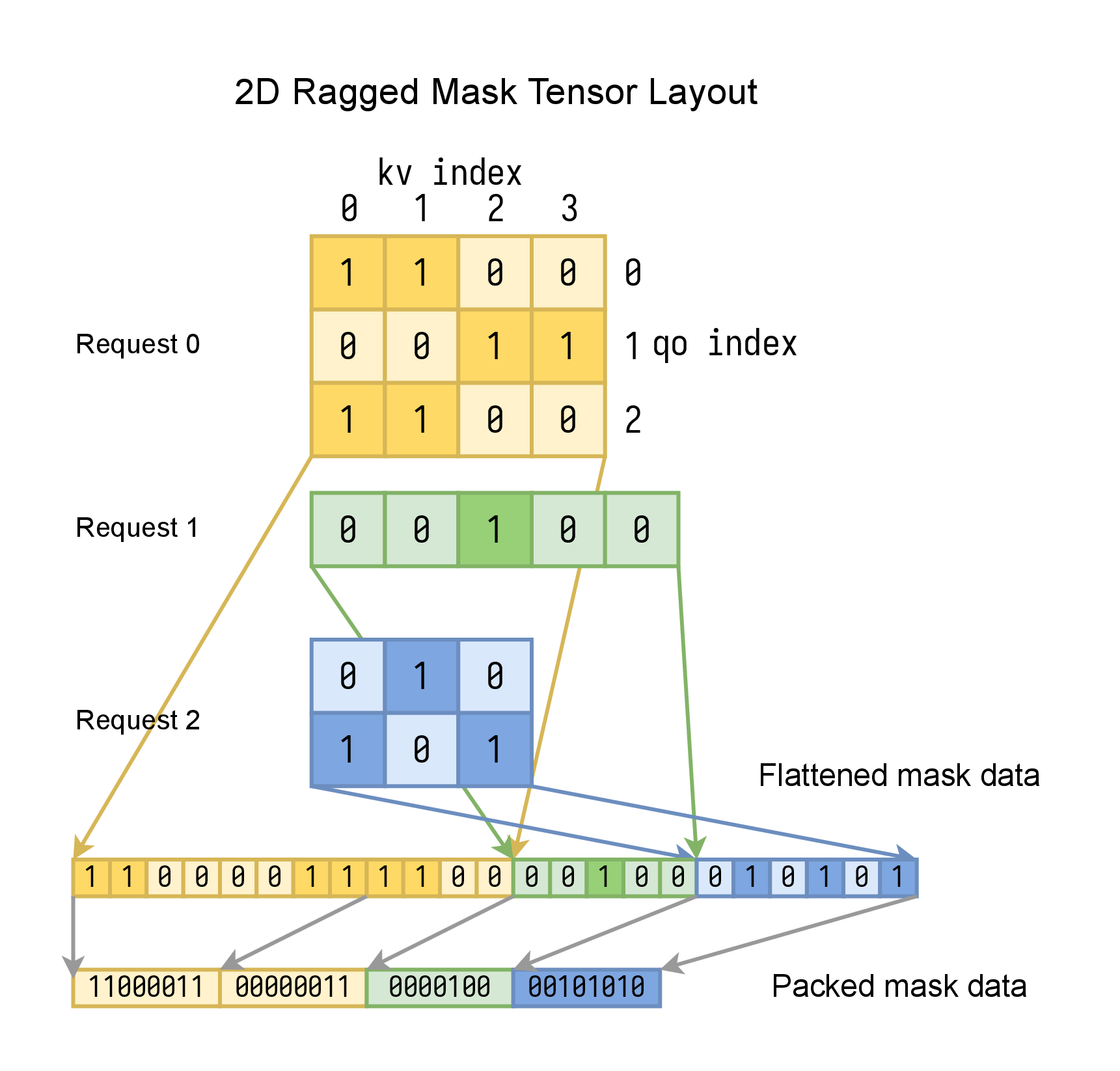
When number of requests is greater than 1, different requests might have different query length and kv length.
To avoid padding, we use a 2D ragged tensor to store attention mask. The input qo_indptr and
kv_indptr arrays (both with length num_requests+1) are used to store the information of
variable sequence lengths of each request,
qo_indptr[i+1]-qo_indptr[i] is the query length of request i (qo_len[i]),
kv_indptr[i+1]-kv_indptr[i] is the kv length of request i (kv_len[i]).
The mask arrays of all requests are flattened (with query as the first dimension, and kv as last dimension)
and concatenated into a single 1D array: mask_data. FlashInfer will create a mask_indptr array implicitly
to store the start offset of each request’s mask in the flattened mask array: mask_indptr[1:] = cumsum(qo_len * kv_len).
mask_data has shape (mask_indptr[-1],), we can use mask_data[mask_indptr[i]:mask_indptr[i+1]] to slice the flattened
mask of request i.
To save memory, we can further pack the flattened boolean mask array into a bit-packed array (1 bit per element, 8 elements are packed together as a uint8) with “little” bit-order (see numpy.packbits for more details). FlashInfer accepts both boolean mask and bit-packed mask. If boolean mask is provided, FlashInfer will pack it into bit-packed array internally.
FlashInfer APIs¶
flashinfer.prefill.BatchPrefillWithPagedKVCacheWrapper and flashinfer.prefill.BatchPrefillWithRaggedKVCacheWrapper
allow user to specify qo_indptr, kv_indptr and custom attention mask custom_mask in begin_forward functions,
the mask data will be added to the attention score before softmax (and after softmax scaling) in the attention kernel.
flashinfer.quantization.packbits() and flashinfer.quantization.segment_packbits() are the utility functions
to pack boolean mask into bit-packed array.
Page Table Layout¶
When KV-Cache is dynamic (e.g. in append or decode stage), packing all keys/values is not efficient because the sequence length per request changes over time. vLLM proposes to organize KV-Cache as a Page Table. In FlashInfer, we treat the page table as a block sparse matrix (each used page can be viewed as an non-zero block in block sparse matrix) and uses the CSR format to index the pages in KV-Cache.
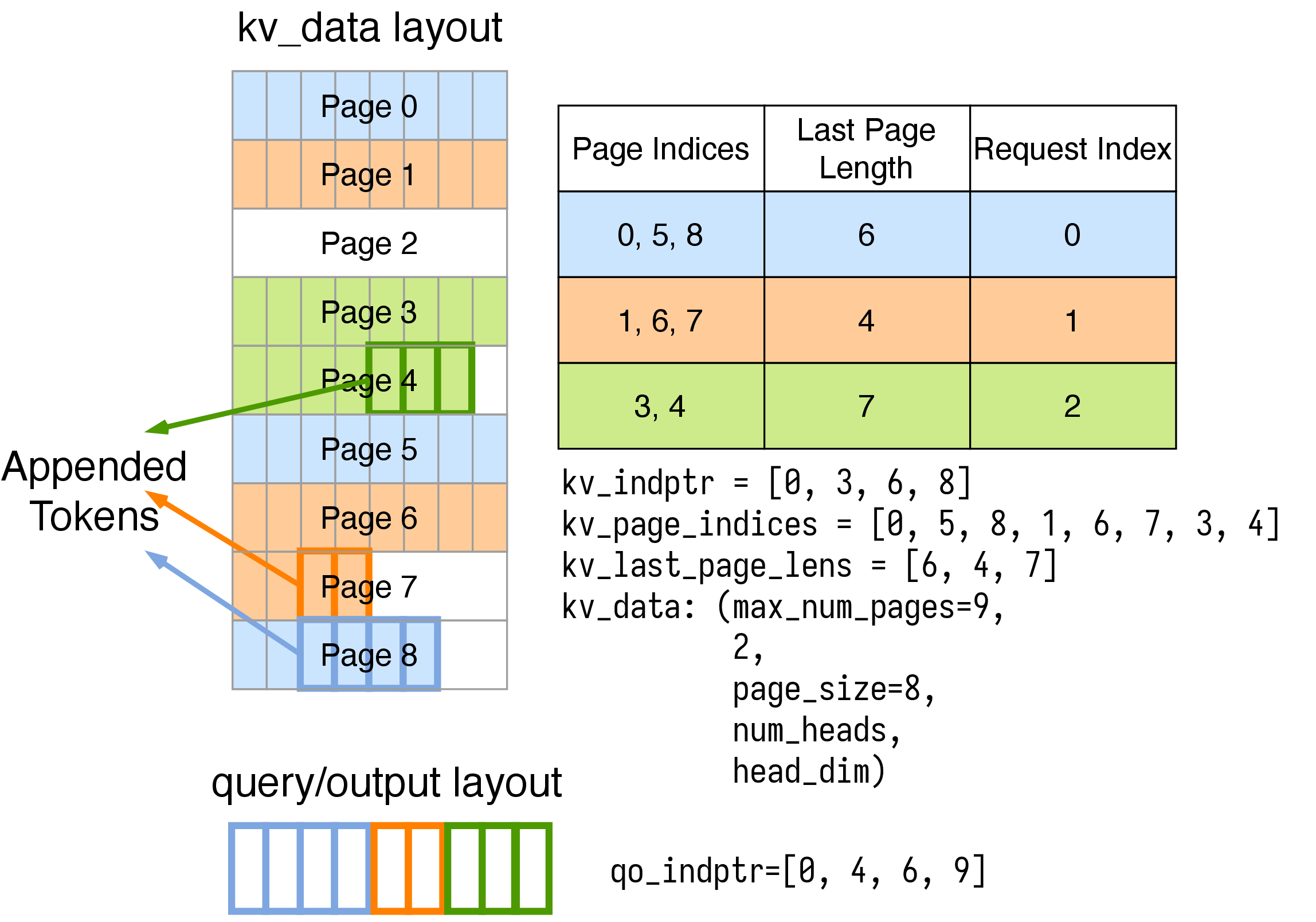
For each request, we keep a record of its page_indices, last_page_len which
tracks the pages used by this request and the number of entries in the last page. The KV
sequence length of request i is page_size * (len(page_indices[i]) - 1) + last_page_length[i].
Note
The last_page_len of each request must be greater than zero, and less than or equal to page_size.
The overall kv_indptr array (with length num_requests+1) can be computed as:
[0, len(page_indices[0]), len(page_indices[0])+len(page_indices[1]), ...].
The overall kv_page_indices array (with length kv_indptr[-1]) is the concatenation of all requests’ page_indices.
The overall kv_last_page_lens array (with length num_requests) is the concatenation of all requests’ last_page_length.
The kv_data tensor could either be a single 5-D tensor or a tuple of 4-D tensors,
when stored in a single tensor, kv_data has shape:
kv_cache_nhd = torch.empty(max_num_pages, 2, page_size, num_heads, head_dim, dtype=torch.bfloat16) # NHD layout
kv_cache_hnd = torch.empty(max_num_pages, 2, num_heads, page_size, head_dim, dtype=torch.bfloat16) # HND layout
when stored in a tuple of tensors, kv_data = (k_data, v_data), and each one of them has shape:
k_cache_nhd = torch.empty(max_num_pages, page_size, num_heads, head_dim, dtype=torch.bfloat16) # NHD layout
k_cache_hnd = torch.empty(max_num_pages, num_heads, page_size, head_dim, dtype=torch.bfloat16) # HND layout
v_cache_nhd = torch.empty(max_num_pages, page_size, num_heads, head_dim, dtype=torch.bfloat16) # NHD layout
v_cache_hnd = torch.empty(max_num_pages, num_heads, page_size, head_dim, dtype=torch.bfloat16) # HND layout
where max_num_pages is the maximum number of pages used by all requests, page_size is the number of tokens
we fit into each page. 2 in single tensor storage means K/V (first one for keys, the second one for values).
Note
indptr arrays across the flashinfer library should be of type int32. Arrays of type int64 can cause indexing errors. This is also true of the kv_page_indices and kv_last_page_lens arrays.
Multi-head Latent Attention Page Layout¶
Multi-head Latent Attention (MLA) is a new attention mechanism proposed in DeepSeek v2 and was
used in later DeepSeek models. MLA unifies key cache and value cache into a single tensor, so there is no need to store them separately.
Compared to multi-head attention or grouped query attention, the KV-Cache of MLA do not have the num_heads dimension,
so there is no distinction like NHD and HND layout.
MLA separates RoPE (Rotary Positional Encoding) dimensions and other head dimensions. We use kpe (key w/ positional encoding) and ckv (compressed key/value)
to name these two components. User can store them in a single Paged KV-Cache:
head_dim_ckv = 512
head_dim_kpe = 64
mla_paged_kv_cache = torch.empty(max_num_pages, page_size, head_dim_ckv + head_dim_kpe, dtype=torch.bfloat16)
ckv = mla_paged_kv_cache[:, :, :head_dim_ckv] # Slicing here does not copy or move data
kpe = mla_paged_kv_cache[:, :, head_dim_ckv:] # Slicing here does not copy or move data
and ckv and kpe can then be fed into the MLA attention kernel flashinfer.mla.BatchMLAPagedAttentionWrapper.
FlashInfer APIs¶
flashinfer.page.append_paged_kv_cache() can append a batch of keys/values (stored as ragged tensors) to the paged KV-Cache
(the pages for these appended keys/values must be allocated prior to calling this API).
flashinfer.decode.BatchDecodeWithPagedKVCacheWrapper and flashinfer.prefill.BatchPrefillWithPagedKVCacheWrapper implements the decode attention
and prefill/append attention between queries stored in ragged tensors and keys/values stored in paged KV-Cache.
Multi-level Cascade Inference Data Layout¶
When using multi-level cascade inference,
the query and output are stored in ragged tensors, and KV-Cache of all levels are stored
in a unified Paged KV-Cache. Each level has a unique qo_indptr array which is the prefix sum of the
accumulated number of tokens to append in the subtree, as well as kv_page_indptr, kv_page_indices, and
kv_last_page_len which has same semantics as in Page Table Layout section. The following figure
introduces how to construct these data structures for append attention operation for 8 requests where we
treat their KV-Cache as 3 levels for prefix reuse:

Note that we don’t have to change the data layout of ragged query/output tensor or paged kv-cache for each level.
All levels share the same underlying data layout, but we use different qo_indptr / kv_page_indptr arrays
so that we can view them in different ways.
FlashInfer APIs¶
FlashInfer provides flashinfer.cascade.MultiLevelCascadeAttentionWrapper to compute
the cascade attention.
FAQ¶
- How do FlashInfer manages KV-Cache?
FlashInfer itself is not responsible for managing the page-table (pop and allocate new pages, etc.) and we leave the strategy to the user: different serving engines might have different strategies to manage the page-table. FlashInfer is only responsible for computing the attention between queries and keys/values stored in KV-Cache.