flashinfer.sparse¶
Kernels for block sparse flashattention.
- class flashinfer.sparse.BlockSparseAttentionWrapper(float_workspace_buffer: Tensor, backend: str = 'auto')¶
Wrapper class for attention computation with a block-sparse matrix as attention mask. The definition of block sparse matrix can be found at bsr_matrix in SciPy.
This API supports any block size
(R, C).Example
>>> import torch >>> import flashinfer >>> num_qo_heads = 32 >>> num_kv_heads = 8 >>> head_dim = 128 >>> # allocate 128MB workspace buffer >>> workspace_buffer = torch.empty(128 * 1024 * 1024, dtype=torch.uint8, device="cuda:0") >>> bsr_wrapper = flashinfer.BlockSparseAttentionWrapper(workspace_buffer) >>> # sparse mask: [[0, 0, 1], [1, 0, 1], [0, 1, 1]] >>> M = 3 >>> N = 3 >>> indptr = torch.tensor([0, 1, 3, 5], dtype=torch.int32, device="cuda:0") >>> indices = torch.tensor([2, 0, 2, 1, 2], dtype=torch.int32, device="cuda:0") >>> bsr_wrapper.plan( ... indptr, ... indices, ... M, ... N, ... 1, # R(block_rows)=1 ... 1, # C(block_columns)=1 ... num_qo_heads, ... num_kv_heads, ... head_dim, ... ) >>> q = torch.randn((M, num_qo_heads, head_dim), dtype=torch.float16, device="cuda:0") >>> k = torch.randn((N, num_kv_heads, head_dim), dtype=torch.float16, device="cuda:0") >>> v = torch.randn((N, num_kv_heads, head_dim), dtype=torch.float16, device="cuda:0") >>> o = bsr_wrapper.run(q, k, v) >>> # use dense implementation with attention mask for comparison >>> mask = torch.tensor([[0, 0, 1], [1, 0, 1], [0, 1, 1]], dtype=torch.bool, device="cuda:0") >>> o_ref = flashinfer.single_prefill_with_kv_cache(q, k, v, custom_mask=mask) >>> torch.allclose(o, o_ref) True
- __init__(float_workspace_buffer: Tensor, backend: str = 'auto') None¶
Constructs of
BlockSparseAttentionWrapper.- Parameters:
float_workspace_buffer (torch.Tensor) – The user reserved float workspace buffer used to store intermediate attention results in the split-k algorithm. The recommended size is 128MB, the device of the workspace buffer should be the same as the device of the input tensors.
backend (str) – The implementation backend, could be
auto/fa2orfa3. Defaults toauto. If set toauto, the function will automatically choose the backend based on the device architecture and kernel availability.
- plan(indptr: Tensor | None, indices: Tensor | None, M: int, N: int, R: int, C: int, num_qo_heads: int, num_kv_heads: int, head_dim: int, mask: Tensor | None = None, packed_mask: Tensor | None = None, causal: bool = False, pos_encoding_mode: str = 'NONE', use_fp16_qk_reduction: bool = False, logits_soft_cap: float | None = None, sm_scale: float | None = None, rope_scale: float | None = None, rope_theta: float | None = None, q_data_type: str | dtype = 'float16', kv_data_type: str | dtype | None = None, o_data_type: str | dtype = 'float16', non_blocking: bool = True, block_mask: Tensor | None = None) None¶
Create auxiliary data structures for block sparse attention.
- Parameters:
indptr (torch.Tensor, optional) – The block index pointer of the block-sparse matrix on row dimension, shape
(MB + 1,), whereMBis the number of blocks in the row dimension. Required for all backends exceptvsa_blackwellandvsa_blackwell_blk64whenblock_maskis provided.indices (torch.Tensor, optional) – The block indices of the block-sparse matrix on column dimension, shape
(nnz,), wherennzis the number of non-zero blocks. The elements inindicesarray should be less thenNB: the number of blocks in the column dimension. Required for all backends exceptvsa_blackwellandvsa_blackwell_blk64whenblock_maskis provided.M (int) – The number of rows of the block-sparse matrix,
MB = ceil_div(M, R).N (int) – The number of columns of the block-sparse matrix,
NB = N // C,Nshould be divisible byC.R (int) – The number of rows in each block.
C (int) – The number of columns in each block.
num_qo_heads (int) – The number of heads in the query/output tensor.
num_kv_heads (int) – The number of heads in the key/value tensor.
head_dim (int) – The dimension of each head.
mask (torch.Tensor, optional) – The mask tensor with shape
(nnz, R, C,), where nnz is the number of non-zero blocks. If every block is full, then we don’t need to provide the mask tensor.packed_mask (torch.Tensor, optional) – The 1D packed mask tensor, if provided, the
custom_maskwill be ignored. The packed mask tensor is generated byflashinfer.quantization.packbits().causal (bool) – Whether to apply causal mask to the attention matrix. This is only effective when
custom_maskis not provided inplan().pos_encoding_mode (str, optional) – The position encoding applied inside attention kernels, could be
NONE/ROPE_LLAMA(LLAMA style rotary embedding) /ALIBI. Default isNONE.use_fp16_qk_reduction (bool) – Whether to use f16 for qk reduction (faster at the cost of slight precision loss).
logits_soft_cap (Optional[float]) – The attention logits soft capping value (used in Gemini, Grok and Gemma-2, etc.), if not provided, will be set to
0. If greater than 0, the logits will be capped according to formula: \(\texttt{logits_soft_cap} \times \mathrm{tanh}(x / \texttt{logits_soft_cap})\), where \(x\) is the input logits.sm_scale (Optional[float]) – The scale used in softmax, if not provided, will be set to
1.0 / sqrt(head_dim).rope_scale (Optional[float]) – The scale used in RoPE interpolation, if not provided, will be set to
1.0.rope_theta (Optional[float]) – The theta used in RoPE, if not provided, will be set to
1e4.q_data_type (str, optional) – The data type of the query tensor.
kv_data_type (Optional[Union[str, torch.dtype]]) – The data type of the key/value tensor. If None, will be set to
q_data_type.o_data_type (str, optional) – The data type of the output tensor. Default is
half. As output dtype cannot be inferred by input dtype in quantizationnon_blocking (bool) – Whether to copy the input tensors to the device asynchronously, defaults to
True.block_mask (torch.Tensor, optional) – Per-head block-level attention mask, dtype bool. Shape may be either
(num_qo_heads, MB, NB)or(num_kv_heads, MB, NB).block_mask[h, i, j] = Truemeans the Q-blockiattends to KV-blockjfor headh. For GQA (num_qo_heads > num_kv_heads), when providing(num_qo_heads, MB, NB), the first QO-head from each KV-head group is used (sparsity must be the same across QO-heads that share a KV-head). Only supported for thevsa_blackwellandvsa_blackwell_blk64backends. When provided,indptr/indicesare not required and will be ignored.
:param The
plan()method should be called before anyrun()or: :paramrun_return_lse()calls: :param auxiliary data structures will be created: :param during this call and cached for multiple kernel runs.: :param Thenum_qo_headsmust be a multiple ofnum_kv_heads. Ifnum_qo_heads: :param is not equal tonum_kv_heads: :param the function will use: :param grouped query attention.:
- reset_workspace_buffer(float_workspace_buffer: Tensor, int_workspace_buffer: Tensor) None¶
Reset the workspace buffer.
- Parameters:
float_workspace_buffer (torch.Tensor) – The new float workspace buffer, the device of the new float workspace buffer should be the same as the device of the input tensors.
int_workspace_buffer (torch.Tensor) – The new int workspace buffer, the device of the new int workspace buffer should be the same as the device of the input tensors.
- run(q: Tensor, k: Tensor, v: Tensor, scale_q: Tensor | None = None, scale_k: Tensor | None = None, scale_v: Tensor | None = None, out: Tensor | None = None, lse: Tensor | None = None, return_lse: bool = False, enable_pdl: bool | None = None) Tensor | Tuple[Tensor, Tensor]¶
Compute block-sparse attention between Q/K/V tensors.
- Parameters:
q (torch.Tensor) – The query tensor with shape
(M, num_qo_heads, head_dim).k (torch.Tensor) – The key tensor with shape
(N, num_kv_heads, head_dim).v (torch.Tensor) – The value tensor with shape
(N, num_kv_heads, head_dim).scale_q (Optional[torch.Tensor]) – The scale tensor for query, per-head quantization with shape:
[num_qo_heads]. Used with FP8 Quantization. If not provided, will be set to1.0.scale_k (Optional[torch.Tensor]) – The scale tensor for key, per-head quantization with shape:
[num_kv_heads]. Used with FP8 Quantization. If not provided, will be set to1.0.scale_v (Optional[torch.Tensor]) – The scale tensor for value, per-head quantization with shape:
[num_kv_heads]. Used with FP8 Quantization. If not provided, will be set to1.0.out (Optional[torch.Tensor]) – The output tensor, if not provided, will be allocated internally.
lse (Optional[torch.Tensor]) – The log-sum-exp of attention logits, if not provided, will be allocated internally.
return_lse (bool) – Whether to return the log-sum-exp of attention logits
enable_pdl (bool) – Whether to enable Programmatic Dependent Launch (PDL). See https://docs.nvidia.com/cuda/cuda-c-programming-guide/#programmatic-dependent-launch-and-synchronization Only supported for >= sm90, and currently only for FA2 and CUDA core decode.
- Returns:
If
return_lseisFalse, the attention output, shape:[M, num_qo_heads, head_dim]. Ifreturn_lseisTrue, a tuple of two tensors:The attention output, shape:
[M, num_qo_heads, head_dim].The logsumexp of attention output, shape:
[M, num_qo_heads].
- Return type:
Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]
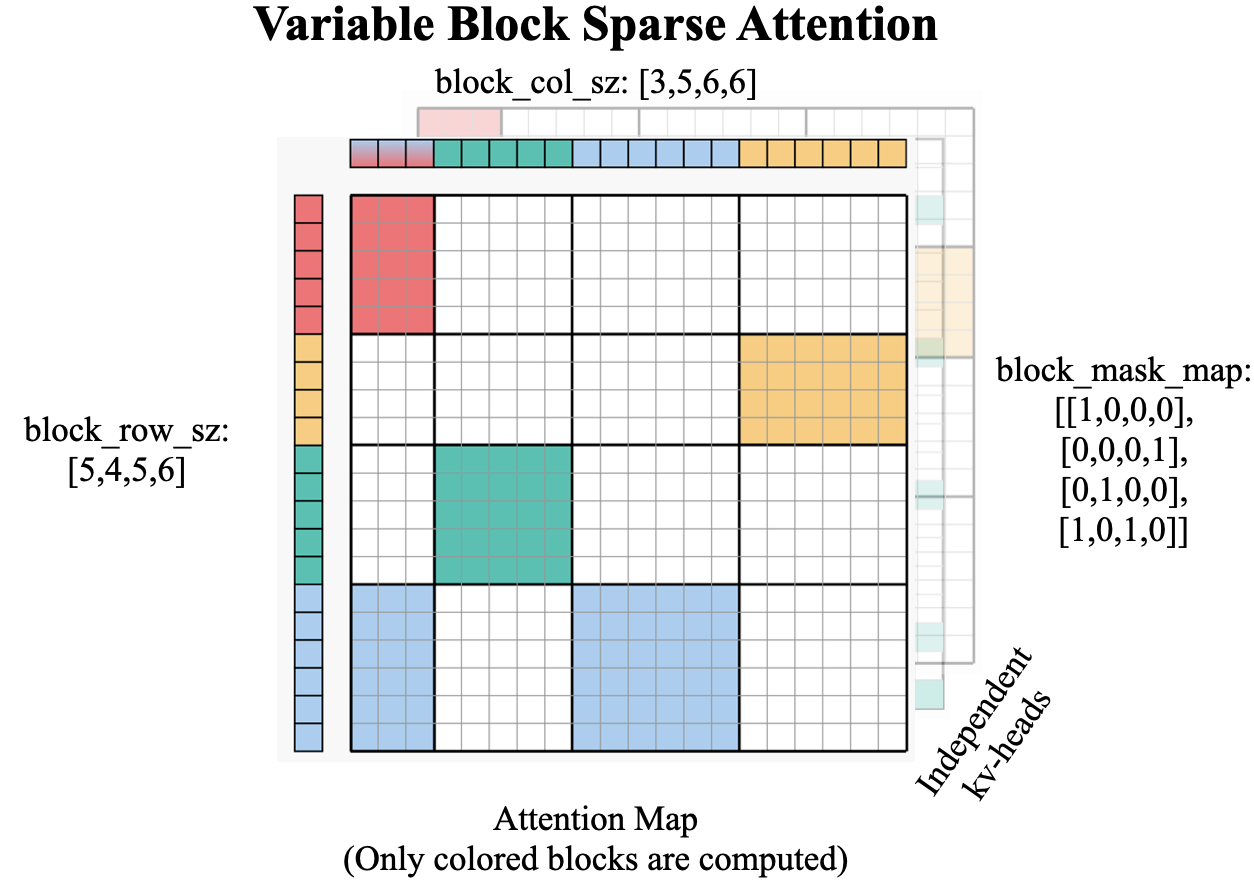
- class flashinfer.sparse.VariableBlockSparseAttentionWrapper(float_workspace_buffer: Tensor, backend: str = 'auto')¶
Wrapper class for attention computation with a block-sparse matrix as attention mask. This API supports variable block sizes provided by
block_row_szandblock_col_sz. Besides, eachkv_head_idxcan specify its own sparse patterns without using the same mask.Example
>>> import torch >>> import flashinfer >>> num_qo_heads = 1 >>> num_kv_heads = 1 >>> head_dim = 128 >>> seq_len = 6 # This corresponds to the `block_row_sz` and `block_col_sz` >>> # allocate 128MB workspace buffer >>> workspace_buffer = torch.empty(128 * 1024 * 1024, dtype=torch.uint8, device="cuda:0") >>> wrapper = flashinfer.VariableBlockSparseAttentionWrapper(workspace_buffer) >>> block_mask_map = torch.tensor([[[0, 0, 1], [1, 0, 1], [0, 1, 1]]], dtype=torch.bool, device="cuda:0") >>> block_row_sz = torch.tensor([[1, 2, 3]], dtype=torch.int32, device="cuda:0") >>> block_col_sz = torch.tensor([[3, 1, 2]], dtype=torch.int32, device="cuda:0") >>> wrapper.plan( ... block_mask_map, ... block_row_sz, ... block_col_sz, ... num_qo_heads, ... num_kv_heads, ... head_dim, ... ) >>> q = torch.randn((num_qo_heads, seq_len, head_dim), dtype=torch.float16, device="cuda:0") >>> k = torch.randn((num_kv_heads, seq_len, head_dim), dtype=torch.float16, device="cuda:0") >>> v = torch.randn((num_kv_heads, seq_len, head_dim), dtype=torch.float16, device="cuda:0") >>> o = wrapper.run(q, k, v)
- __init__(float_workspace_buffer: Tensor, backend: str = 'auto') None¶
Constructs of
VariableBlockSparseAttentionWrapper.- Parameters:
float_workspace_buffer (torch.Tensor) – The user reserved float workspace buffer used to store intermediate attention results in the split-k algorithm. The recommended size is 128MB, the device of the workspace buffer should be the same as the device of the input tensors.
backend (str) – The implementation backend, could be
auto/fa2orfa3. Defaults toauto. If set toauto, the function will automatically choose the backend based on the device architecture and kernel availability.
- plan(block_mask_map: Tensor, block_row_sz: Tensor, block_col_sz: Tensor, num_qo_heads: int, num_kv_heads: int, head_dim: int, causal: bool = False, pos_encoding_mode: str = 'NONE', use_fp16_qk_reduction: bool = False, logits_soft_cap: float | None = None, sm_scale: float | None = None, rope_scale: float | None = None, rope_theta: float | None = None, non_blocking: bool = True, q_data_type: str | dtype = 'float16', kv_data_type: str | dtype | None = None) None¶
Create auxiliary data structures for block sparse attention.
- Parameters:
block_mask_map (torch.Tensor) – The block mask map (boolean), shape
(num_kv_heads, MB, NB), whereMBis the number of blocks in the row dimension,NBis the number of blocks in the column dimension.block_row_sz (torch.Tensor) – The block row size, shape
(num_kv_heads, MB,).block_col_sz (torch.Tensor) – The block column size, shape
(num_kv_heads, NB,).num_qo_heads (int) – The number of heads in the query/output tensor.
num_kv_heads (int) – The number of heads in the key/value tensor. Note that a group of
qo_headsshares the same sparse pattern ofkv_heads.head_dim (int) – The dimension of each head.
causal (bool) – Whether to apply causal mask to the attention matrix.
pos_encoding_mode (str, optional) – The position encoding applied inside attention kernels, could be
NONE/ROPE_LLAMA(LLAMA style rotary embedding) /ALIBI. Default isNONE.use_fp16_qk_reduction (bool) – Whether to use f16 for qk reduction (faster at the cost of slight precision loss).
logits_soft_cap (Optional[float]) – The attention logits soft capping value (used in Gemini, Grok and Gemma-2, etc.), if not provided, will be set to
0. If greater than 0, the logits will be capped according to formula: \(\texttt{logits_soft_cap} \times \mathrm{tanh}(x / \texttt{logits_soft_cap})\), where \(x\) is the input logits.sm_scale (Optional[float]) – The scale used in softmax, if not provided, will be set to
1.0 / sqrt(head_dim).rope_scale (Optional[float]) – The scale used in RoPE interpolation, if not provided, will be set to
1.0.rope_theta (Optional[float]) – The theta used in RoPE, if not provided, will be set to
1e4.non_blocking (bool) – Whether to copy the input tensors to the device asynchronously, defaults to
True.q_data_type (Union[str, torch.dtype]) – Dtype of the query tensor. Used to specialize the JIT-compiled kernel. Defaults to
"float16".kv_data_type (Optional[Union[str, torch.dtype]]) – Dtype of the key/value tensors. When
None, defaults toq_data_type.
The
plan()method should be called before anyrun()orrun_return_lse()calls, auxiliary data structures will be created during this call and cached for multiple kernel runs.The
num_qo_headsmust be a multiple ofnum_kv_heads. Ifnum_qo_headsis not equal tonum_kv_heads, the function will use grouped query attention.
- reset_workspace_buffer(float_workspace_buffer: Tensor, int_workspace_buffer: Tensor) None¶
Reset the workspace buffer.
- Parameters:
float_workspace_buffer (torch.Tensor) – The new float workspace buffer, the device of the new float workspace buffer should be the same as the device of the input tensors.
int_workspace_buffer (torch.Tensor) – The new int workspace buffer, the device of the new int workspace buffer should be the same as the device of the input tensors.
- run(q: Tensor, k: Tensor, v: Tensor, out: Tensor | None = None, lse: Tensor | None = None, return_lse: bool = False, enable_pdl: bool | None = None) Tensor | Tuple[Tensor, Tensor]¶
Compute block-sparse attention between Q/K/V tensors.
- Parameters:
q (torch.Tensor) – The query tensor with shape
(num_qo_heads, qo_len, head_dim).k (torch.Tensor) – The key tensor with shape
(num_kv_heads, kv_len, head_dim).v (torch.Tensor) – The value tensor with shape
(num_kv_heads, kv_len, head_dim).out (Optional[torch.Tensor]) – The output tensor, if not provided, will be allocated internally.
lse (Optional[torch.Tensor]) – The log-sum-exp of attention logits, if not provided, will be allocated internally.
return_lse (bool) – Whether to return the log-sum-exp of attention logits
enable_pdl (bool) – Whether to enable Programmatic Dependent Launch (PDL). See https://docs.nvidia.com/cuda/cuda-c-programming-guide/#programmatic-dependent-launch-and-synchronization Only supported for >= sm90, and currently only for FA2 and CUDA core decode.
- Returns:
If
return_lseisFalse, the attention output, shape:[M, num_qo_heads, head_dim]. Ifreturn_lseisTrue, a tuple of two tensors:The attention output, shape:
[M, num_qo_heads, head_dim].The logsumexp of attention output, shape:
[M, num_qo_heads].
- Return type:
Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]
flashinfer.msa_ops¶
Minimax Sparse Attention (MSA) APIs for SM120/SM121 (Blackwell).
|
MSA dense proxy pass for SM120/SM121: per-KV-block max attention logits. |
|
NVFP4 MSA dense proxy pass for SM120/SM121 (the FP4 counterpart of |
|
Minimax Sparse Attention forward (prefill) for SM120/SM121. |
|
Sparse decode attention for SM120/SM121. |
|
Select the top-K KV blocks per query token based on attention scores. |